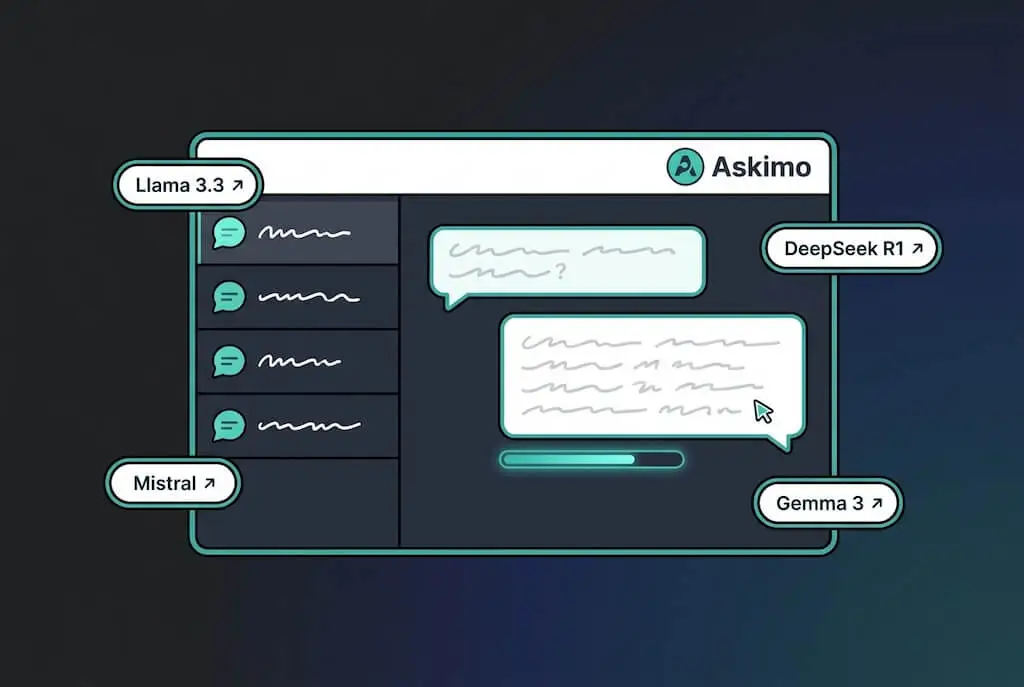
Wenn du nach einer Ollama Desktop-App, einer Ollama-GUI, einem Ollama-Client oder einer schnellen Ollama-Chat-Oberfläche zum Ausführen lokaler KI-Modelle auf macOS, Windows oder Linux suchst, stellt dir dieser Guide die Askimo App als eine Option vor, die du dir ansehen solltest. Askimo bietet ein natives Ollama Desktop-Erlebnis für lokale Modelle wie Llama 3.3, DeepSeek R1, Mistral, Gemma 3, Qwen 2.5, Phi-4 und Hunderte weiterer Ollama-Modelle – und unterstützt gleichzeitig Cloud-Anbieter wie OpenAI, Claude und Gemini in einer einheitlichen Oberfläche.
TL;DR: Installiere Ollama, lade die Askimo App GUI herunter, konfiguriere Askimo zur Verbindung mit
http://localhost:11434, wähle dein bevorzugtes Ollama-Modell (llama3.3,deepseek-r1,mistral,gemma3,qwen2.5) und starte Chats mit vollständig durchsuchbaren, organisierbaren und exportierbaren lokalen KI-Unterhaltungen.
Warum eine Ollama Desktop-GUI statt CLI oder Web-UI verwenden?
Die Ollama-CLI (Command Line Interface) ist zwar mächtig für schnelle Prompts, aber eine dedizierte Ollama Desktop-App wie Askimo ergänzt sie um essenzielle Produktivitätsfunktionen für ernsthafte KI-Workflows:
- Persistente Unterhaltungshistorie über alle deine Ollama-Chat-Sessions hinweg
- Volltextsuche im Chat, um Nachrichten innerhalb deiner Ollama-Unterhaltungen zu finden
- Wichtige Ollama-Chats markieren und anpinnen für sofortigen Zugriff
- Ollama-Chats als Markdown, JSON oder HTML exportieren für Doku, Notizen oder das Teilen im Team
- Ein-Klick-Anbieterwechsel zwischen lokalen KI-Anbietern und Cloud-KI-Anbietern
- Projektbasiertes RAG für kontextbewusste Gespräche mit deinen Projekten über lokale Ollama-Modelle
- Eigene Themes, Tastaturkürzel und strukturierte Workflows für Ollama
- Lazy Loading für sehr lange Chats (Askimo lädt ältere Ollama-Nachrichten nur beim Hochscrollen nach)
Askimo verwandelt lokale Ollama-Experimente von verstreuten Terminalbefehlen in einen wiederholbaren, professionellen Desktop-Workflow.
Warum die Ollama Desktop-Performance von Askimo Web-UIs übertrifft:
Die meisten „Ollama Desktop“-Apps und Ollama Web-UIs rendern die komplette Unterhaltung im DOM. Sobald deine Ollama-Chats mit lokalen Modellen wie Llama 3 oder Mistral auf Hunderte oder Tausende Nachrichten anwachsen, steigt der Speicherverbrauch stark an und die Ollama-GUI beginnt zu ruckeln. Scrollen stockt, Eingaben werden verzögert und das Rendering wird langsam.
Der Ollama Desktop-Client von Askimo geht einen anderen Weg. Er ist mit einem „native-first“, ressourcenschonenden Design speziell für Ollama-Workflows gebaut: Nachrichten streamen ein, während du mit deinen lokalen Modellen chattest, und ältere Verlaufsdaten bleiben virtualisiert. Ältere Ollama-Nachrichten werden nur beim Hochscrollen geladen. So bleibt der Speicherverbrauch niedrig und die Desktop-Performance von Ollama durchgängig flüssig – selbst während langer Recherchesessions oder großer Coding-Unterhaltungen mit Llama 3.3, DeepSeek R1, Mistral oder Qwen 2.5.
Vergleich: Askimo Ollama Desktop vs Terminal-CLI vs Web-UI
| Workflow-Funktion | Nur Ollama-Terminal | Generische Ollama Web-UI | Askimo Ollama Desktop |
|---|---|---|---|
| Multi-Provider-Support | Manuelle Skripte | Meist nur Ollama | Integrierter Provider-Switcher |
| Chat-Historie | Keine automatischen Logs | Einfach/unterschiedlich | Organisiert & durchsuchbar |
| Exportoptionen | Manuelles Kopieren | Selten | Export als Markdown, JSON & HTML |
| Chats markieren / organisieren | Nicht verfügbar | Eingeschränkt | Favoriten + strukturierte Sessions |
| Lokale Privatsphäre | Vollständig lokal | Abhängig vom Tool | Lokale KI + optionale Cloud |
| Plattformübergreifend | Linux/macOS/Win | Sehr unterschiedlich | Linux/macOS/Win |
Schritt 1: Ollama auf macOS, Windows oder Linux installieren
Ollama läuft lokal auf macOS, Windows und Linux.
- macOS
Installer herunterladen: https://ollama.com/download/mac
- Windows
Installer herunterladen: https://ollama.com/download/windows
- Linux
curl -fsSL https://ollama.com/install.sh | shInstallation testen:
ollama run llama3.3Falls ein Modell noch nicht heruntergeladen wurde, lädt Ollama es automatisch.
Populäre Ollama-Modelle im Jahr 2026
| Modell | Pull-Befehl | Am besten geeignet für |
|---|---|---|
| Llama 3.3 (70B) | ollama pull llama3.3 |
Allgemeiner Chat, Reasoning |
| DeepSeek R1 (8B) | ollama pull deepseek-r1:8b |
Coding, schrittweises Reasoning |
| DeepSeek R1 (32B) | ollama pull deepseek-r1:32b |
Fortgeschrittenes Reasoning, Recherche |
| Mistral (7B) | ollama pull mistral |
Schneller, leichter Chat |
| Gemma 3 (4B) | ollama pull gemma3:4b |
Effizient, wenig VRAM |
| Qwen 2.5 (7B) | ollama pull qwen2.5:7b |
Mehrsprachig, Coding |
| Phi-4 (14B) | ollama pull phi4 |
Reasoning, kleiner Footprint |
Unsicher, womit du starten sollst? mistral oder gemma3:4b sind gute Optionen für die meisten Rechner. Verwende deepseek-r1 oder llama3.3, wenn du 16 GB+ RAM hast.
Schritt 2: Askimo App installieren (Ollama-GUI)
Askimo App Binaries:
- Installationsanleitung für macOS
- Installationsanleitung für Windows
- Installationsanleitung für Linux
Öffne die App (Programme-Ordner / Startmenü) und fahre mit der Provider-Einrichtung fort.
Schritt 3: Askimo App mit deinem Ollama-Server verbinden
Askimo erkennt den standardmäßigen Ollama-Endpunkt automatisch:
http://localhost:11434Wenn du Ports oder Remotezugriff geändert hast, passe ihn manuell an.
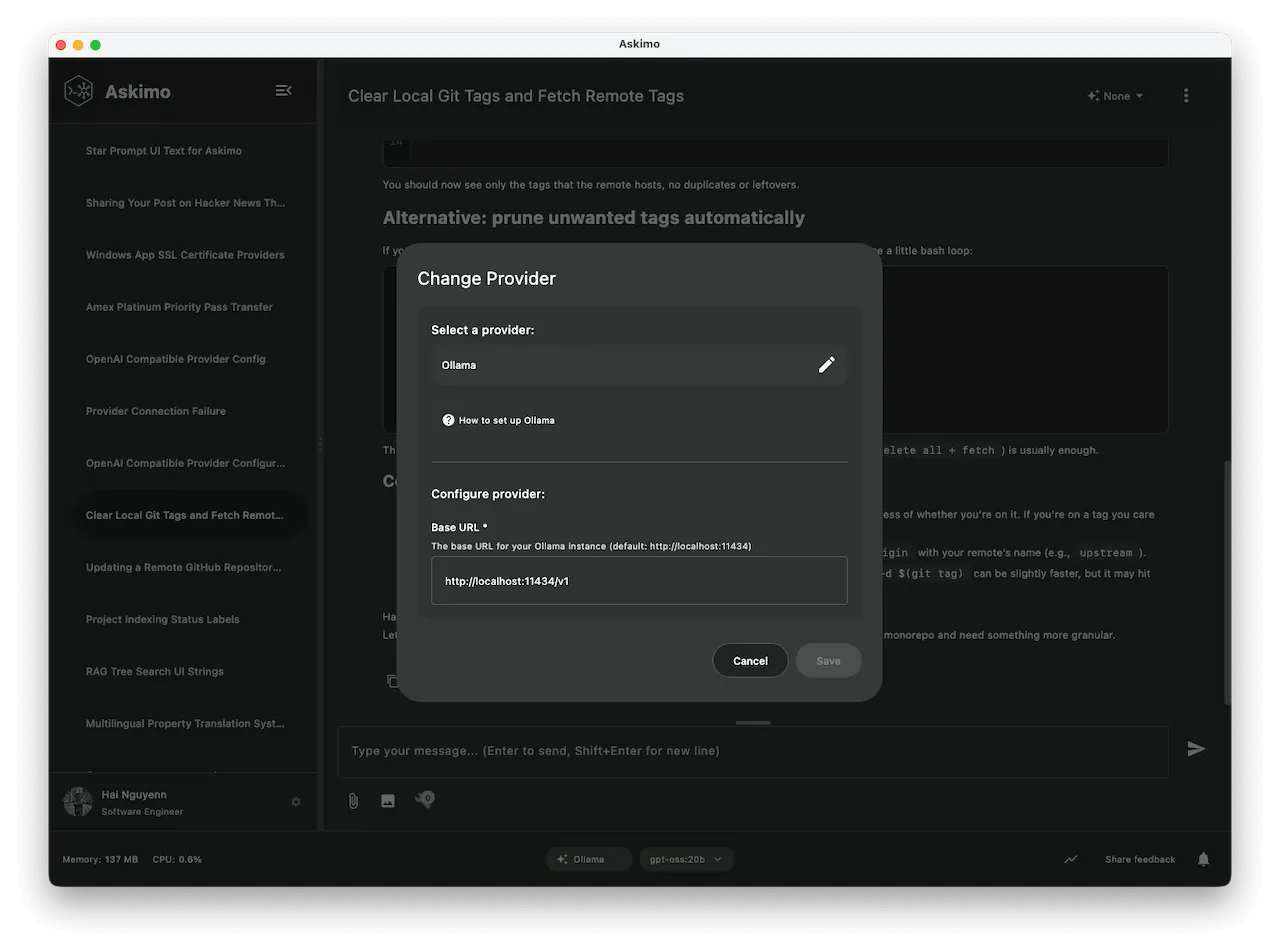
- Öffne die Askimo App
- Wähle den Provider in der Fußzeile der Askimo App oder gehe zu Settings > AI Providers
- Wähle Ollama
- Stelle sicher, dass Endpoint =
http://localhost:11434ist - Wähle ein Modell (z. B.
llama3.3,deepseek-r1:8b,mistral,gemma3:4b,qwen2.5:7busw.) - Speichern & mit dem Chatten beginnen
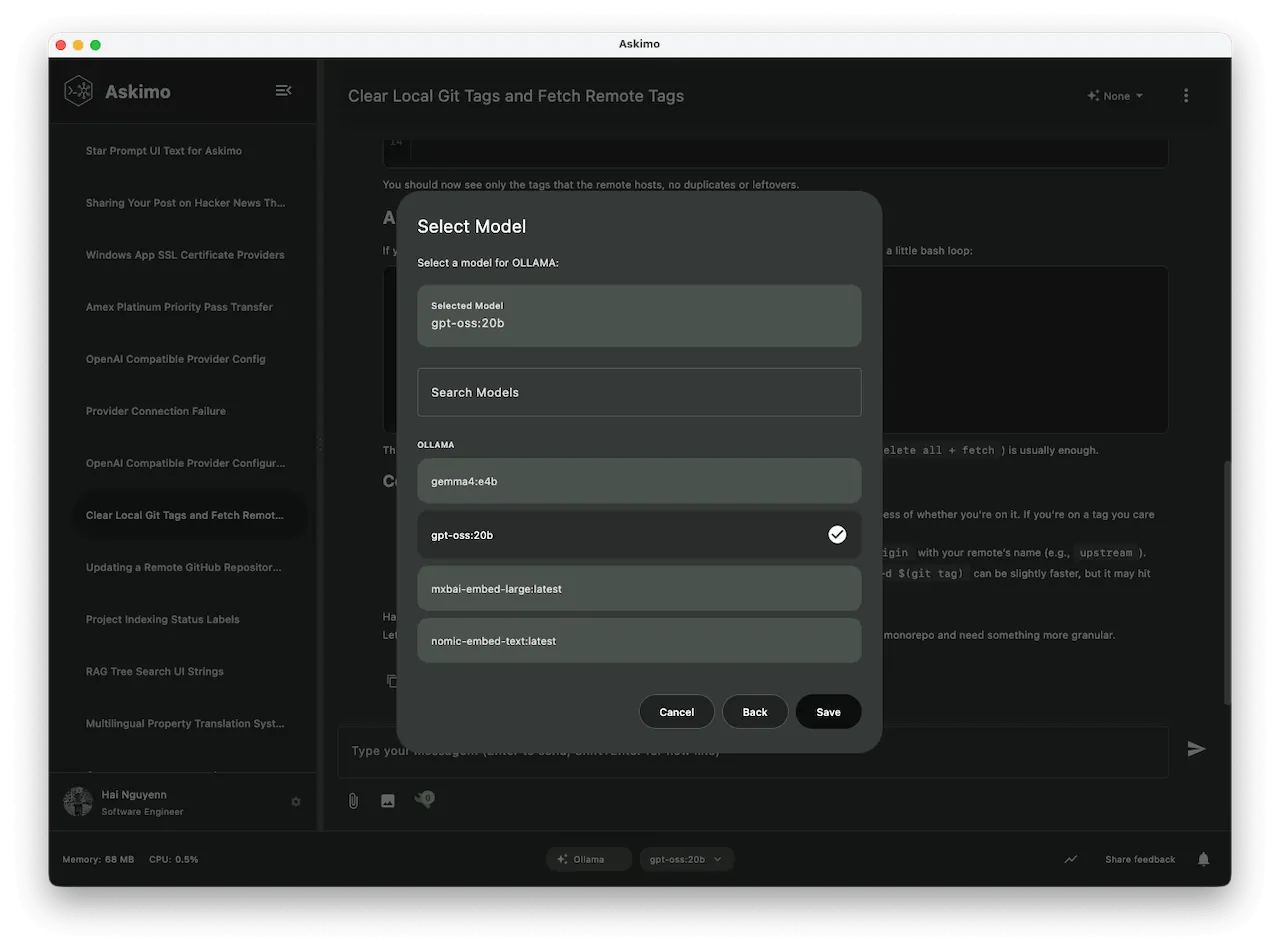
Wechsle Ollama-Modelle sofort – ganz ohne Terminalbefehle.
Askimo Ollama Desktop-App: Feature-Deep-Dive
Im Folgenden ein detaillierter Blick darauf, was Askimo von „nur einem weiteren Ollama-Wrapper“ unterscheidet. Du kannst bei Bedarf Screenshots an den angegebenen Stellen einfügen.
1. Performance & Ressourceneffizienz für Ollama-Chat
- Lazy Loading älterer Ollama-Nachrichten (virtualisierte Historie für riesige Chats)
- Streaming von Ollama-Antworten mit flüssigem, inkrementellem Rendering
- Minimaler DOM-Footprint im Vergleich zu Ollama Web-Wrappers, die ganze Threads neu rendern
- Effiziente Speichernutzung für Ollama-Recherchesessions mit Hunderten von Turns
2. Mehrere KI-Modelle & Ollama-Modelmanagement
- Sofortiger Wechsel zwischen lokalen KI-Providern (Ollama und andere) sowie Cloud-Providern (OpenAI, Claude, Gemini)
- Schneller Modellselektor (z. B. Wechsel von
llama3→mistralfür mehr Geschwindigkeit) - Automatische Endpunkt-Erkennung für lokales Ollama
3. Suche & Wissensorganisation für Ollama-Unterhaltungen
- Volltextsuche im Chat, um jede Nachricht innerhalb deiner Ollama-Sessions zu finden
- Schnelles Keyword-Filtering, um gezielt Infos in langen Chats aufzuspüren
- Markieren / Anpinnen wichtiger Ollama-Threads für schnellen Zugriff und einfaches Wiederfinden
4. Chat-Thread-Utilities für Ollama-Sessions
- One-Click-Export als Markdown, JSON oder HTML (sauberes, dev-freundliches Format)
- Teilbare Ollama-Transkripte für Docs / PRDs / Spezifikationen
- Wichtige Ollama-Sessions markieren, Markierung entfernen und neu anordnen
5. UI, Personalisierung & Barrierefreiheit für Ollama Desktop
- Light- & Dark-Themes (Theme-Wechsel ohne Reload)
- Schriftanpassung (bessere Lesbarkeit für lange Ollama-Sessions)
- Tastaturkürzel für: neuen Chat, Providerwechsel, Suchfokus, Export
- Sanftes Scrollen und stabile Layouts (kein Springen während des Ollama-Streamings)
6. Datenschutz & Local-First-Workflow mit Ollama
- Antworten lokaler Modelle verlassen deinen Rechner nie (bei Nutzung lokaler KI-Provider wie Ollama)
- Cloud-Provider nur, wenn du sie explizit auswählst
- Exporte bleiben lokal, solange du sie nicht aktiv teilst
- Kein stilles Background-Syncing oder Analytics für Inhalte
7. Custom Directives in Askimo für Ollama-Modelle
Custom Directives erlauben dir festzulegen, wie sich die KI beim Ausführen von lokalen KI-Modellen verhält. Statt lange Anweisungen bei jedem neuen Chat neu zu schreiben, definierst du deine Präferenzen einmal, und Askimo wendet sie automatisch in allen Unterhaltungen an.
-
Konsistentes Verhalten für lokale Modelle Halte deine Chats mit Llama 3.3, DeepSeek R1, Mistral, Gemma 3 oder Qwen 2.5 konsistent in Ton, Stil und Detailtiefe, wie du es bevorzugst.
-
Aufgabenbezogene Presets für wiederkehrende Workflows Lege Direktiven für Coding, Debugging, Paper-Zusammenfassungen, Dokumentationsgenerierung oder jede andere wiederkehrende Aufgabe mit lokalen KI-Modellen an.
-
Sofortiges Umschalten ohne Prompt-Ballast Wechsle Direktiven mit einem Klick, statt bei jeder Nachricht Textblöcke mit Anweisungen einzufügen.
-
Optimiert für lange Sessions mit lokaler Inferenz Direktiven helfen lokalen Modellen, fokussiert zu bleiben und unnötiges Hin und Her zu reduzieren – ideal für lange Recherche- oder Coding-Sessions.
8. Projektbasiertes RAG mit lokalen Ollama-Modellen
Die RAG-Funktion (Retrieval-Augmented Generation) von Askimo ermöglicht dir, mit deinem gesamten Projekt über lokale Ollama-Modelle zu chatten. Anstatt Inhalte manuell in Prompts zu kopieren, ruft Askimo automatisch relevanten Kontext aus deinen Projektdateien ab. Lies unseren vollständigen Guide zum Chatten mit Dokumenten über Ollama RAG für eine komplette Schritt-für-Schritt-Anleitung.
-
Kontextbewusste Unterhaltungen mit deinen Projekten Stelle Fragen zu deiner Arbeit und erhalte Antworten, die in deinen tatsächlichen Dateien verankert sind – mit Llama 3.3, DeepSeek R1, Mistral oder anderen Ollama-Modellen. Funktioniert mit Codeprojekten, Dokumentation, wissenschaftlichen Arbeiten, Schreibprojekten und mehr.
-
Automatische Kontextabfrage Askimo indexiert deine Projektdateien und zieht automatisch relevanten Inhalt in den Gesprächskontext.
-
Privacy-first lokales RAG Deine Dateien verlassen deinen Rechner nie, wenn du RAG mit lokalen Ollama-Modellen verwendest – im Gegensatz zu Cloud-Assistenten.
-
Verständnis über mehrere Dateien hinweg Stelle Fragen, die sich über mehrere Dateien erstrecken, und Ollama-Modelle erhalten relevanten Kontext aus deinem gesamten Projekt.
Beispiel-Use-Cases:
- Softwareprojekte: „Erkläre mir den Authentifizierungs-Flow“ oder „Wo werden die Benutzerdaten validiert?“
- Dokumentation: „Fasse die wichtigsten Änderungen in der API-Dokumentation zusammen“ oder „Wie läuft der Installationsprozess ab?“
- Research Papers: „Welche Methodik habe ich in Kapitel 3 verwendet?“ oder „Finde alle Referenzen zu Klimadaten“
- Schreibprojekte: „Welche Themen ziehen sich durch alle Kapitel?“ oder „Liste alle Interaktionen der Figuren mit John auf“
- Technische Spezifikationen: „Was sind die Systemanforderungen?“ oder „Wie ist Modul A mit Modul B verbunden?“
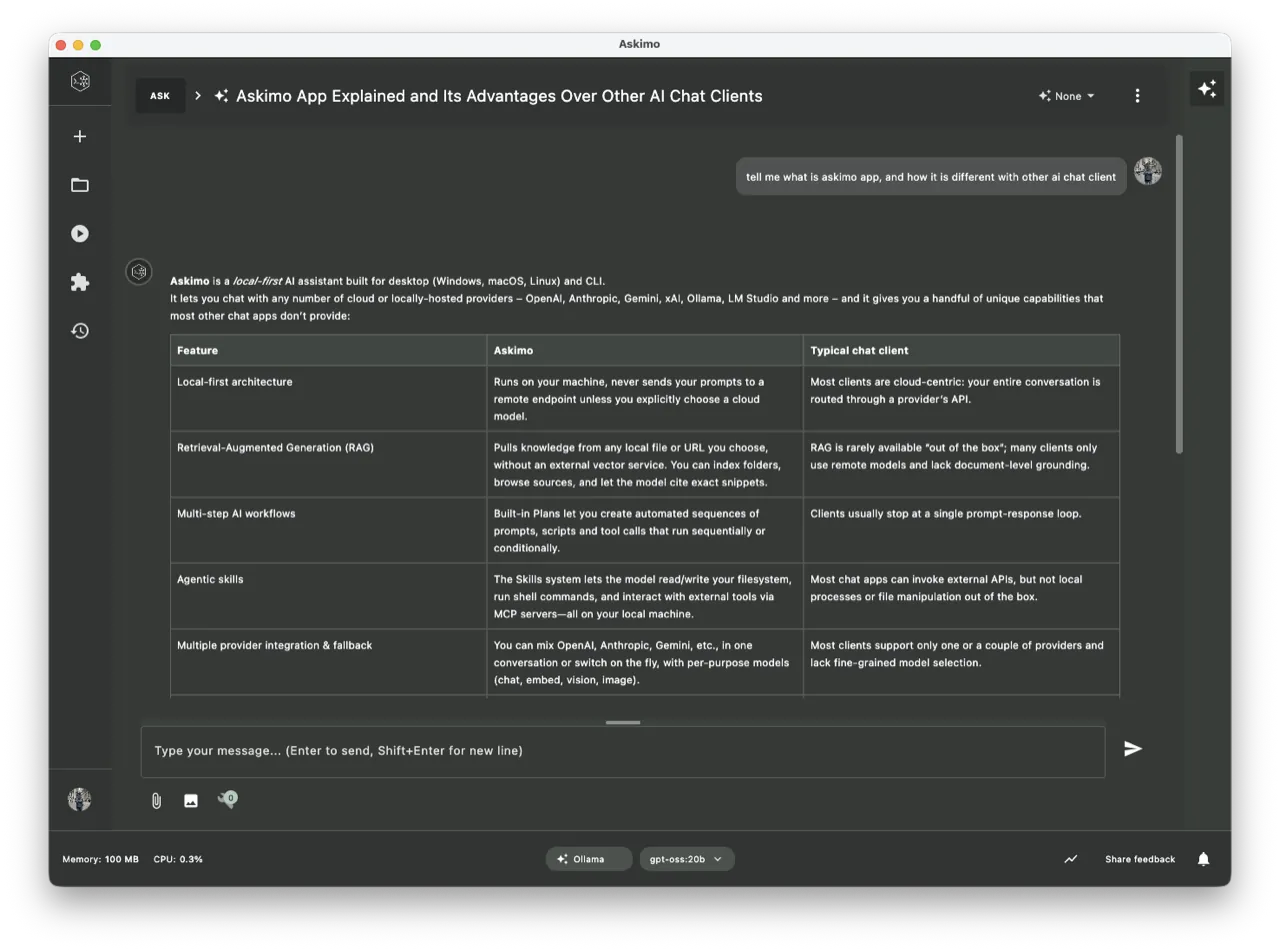
Funktionen, die Askimo von anderen Ollama-GUIs abheben
- Vereinheitlichter Multi-KI-Chat (lokal + gehostet)
- Strukturierte Organisation mit Suche, Favoriten und Exportoptionen
- Native Desktop-Erfahrung mit macOS- und Windows-Installern
- Mehrere Exportformate (Markdown, JSON, HTML) speziell für Entwickler- und Research-Workflows
- Projektbasiertes RAG für Unterhaltungen mit deinen Projekten über lokale Ollama-Modelle (deine Dateien bleiben privat) — erfahre hier, wie du es einrichtest
- Nahtlose Erweiterbarkeit durch eine gemeinsame CLI- und Desktop-Architektur
Andere Ollama-Oberflächen konzentrieren sich hauptsächlich darauf, ein Chatfenster bereitzustellen. Askimo ist auf langfristige Produktivität, strukturiertes Wissen und schnelle Workflows über lokale und Cloud-Modelle hinweg ausgelegt.
Häufige Suchfragen (FAQ)
Hat Ollama eine offizielle Desktop-GUI?
Nein. Ollama bietet eine CLI und eine lokale API, aber keine offizielle GUI. Die Askimo App ist ein voll ausgestatteter Desktop-Client, der sich lokal mit Ollama verbindet.
Was ist eine gute Ollama Desktop-App für macOS oder Windows?
Askimo bietet Modellwechsel zwischen mehreren KI-Anbietern, Suche, Markierungen, Export und eine ausgearbeitete UX für den täglichen Einsatz auf macOS und Windows.
Kann ich Ollama-Modelle und Cloud-Modelle gemeinsam nutzen?
Ja. Mit Askimo kannst du lokale KI-Modelle (inklusive Ollama) ausführen und mit einem Klick zu OpenAI, Claude oder Gemini wechseln.
Sind meine Daten bei der Nutzung von Askimo mit Ollama privat?
Ja. Die gesamte lokale Inferenz läuft über deine Ollama-Installation. Askimo kommuniziert bei der Nutzung von Ollama ausschließlich mit deinem lokalen Endpunkt. Erfahre mehr darüber, wie Askimo deine Daten schützt und keine sensiblen Informationen sammelt, austauscht oder speichert.
Warum sind Antworten mit Ollama langsam?
Große Modelle (wie DeepSeek R1 32B oder Llama 3.3 70B) benötigen starke Hardware. Wähle kleinere Modelle wie mistral, gemma3:4b oder deepseek-r1:8b für schnellere Antworten auf schwächerer Hardware.
Wie ändere ich Ollama-Modelle in Askimo?
Wähle den Provider in der Fußzeile der Askimo App oder gehe zu Settings > AI Providers und aktualisiere dort das Modell. Du kannst ein Modell vorab herunterladen mit:
ollama pull deepseek-r1:8bollama pull mistralollama pull gemma3:4bKann ich Askimo + Ollama offline nutzen?
Ja. Sobald die Modelle heruntergeladen sind, funktionieren sowohl Askimo als auch Ollama vollständig offline.
Kann ich Askimo mit meinen Projekten über Ollama verwenden?
Ja. Die RAG-Funktion von Askimo erlaubt dir, mit deinem gesamten Projekt über lokale Ollama-Modelle zu chatten. Egal ob Code, Dokumentation, wissenschaftliche Arbeiten oder Schreibprojekte – deine Dateien werden lokal indexiert und relevanter Kontext wird automatisch zu Unterhaltungen hinzugefügt. Alles bleibt privat auf deinem Rechner. Sieh dir unseren vollständigen RAG-Guide für Setup-Anleitung und Praxisbeispiele an.
Troubleshooting
Modell antwortet nicht
Prüfe, ob der Ollama-Service läuft:
ollama listWenn die Liste leer ist, starte den Server, indem du ein Modell ausführst:
ollama run mistralEndpunkt nicht erreichbar
Stelle sicher, dass Port 11434 aktiv ist. Wenn du den Port angepasst hast, aktualisiere die Provider-Einstellungen in Askimo.
Langsame Antworten
Nutze ein kleineres Modell oder schließe ressourcenintensive Anwendungen.
Fehler „Modell fehlt“
Ziehe das Modell explizit:
ollama pull deepseek-r1:8b# oderollama pull gemma3:4bAskimo vs andere Ollama Desktop-Apps & Ollama-GUIs
Wenn du Ollama Desktop-Clients und Ollama-GUI-Optionen für macOS, Windows oder Linux vergleichst, hier ist, wie Askimo abschneidet:
Askimo Ollama Desktop vs Open WebUI:
- Askimo: Native Desktop-App (Installer für macOS, Windows, Linux) mit optimierter Performance für Ollama-Chat
- Open WebUI: Browserbasierte Ollama-Oberfläche, die Docker benötigt und als lokaler Webserver läuft
- Askimo-Vorteil: Multi-Provider-Support (Ollama + OpenAI + Claude + Gemini) in einer einzigen nativen App. Askimo enthält außerdem AI Plans – einen integrierten Multi-Step-Workflow-Builder, der Prompts automatisch verkettet (Research → Analyse → Schreiben), ganz ohne Code – und Skills – einen Agent-Runner, der Aufgaben direkt an Gemini CLI, Claude Code oder Codex CLI delegiert, mit vollständigem Lese-/Schreibzugriff auf deine lokalen Dateien. Open WebUI bietet Python-basierte Pipelines und geplante Automationen, diese erfordern jedoch Scripting und Serverkonfiguration. Askimos Plans und Skills sind für den täglichen Desktop-Einsatz konzipiert – ohne weiteren Setup-Aufwand außer der Installation der App.
Askimo vs Ollama Terminal-CLI:
- Askimo: Vollständige Unterhaltungshistorie, Suche, Export, RAG und Organisation für Ollama-Chats
- CLI: Einfache Prompt/Response-Interaktion ohne Persistenz oder Chat-Management
- Askimo-Vorteil: Professioneller Ollama-Workflow mit Tastaturkürzeln und Themes
Askimo vs generische Ollama Web-UIs:
- Askimo: Lazy Loaded Ollama-Nachrichten für flüssige Performance selbst bei >1000 Nachrichten pro Chat
- Web-UIs: Volles DOM-Rendering führt in langen Ollama-Unterhaltungen zu Lags
- Askimo-Vorteil: Native Desktop-Geschwindigkeit und Ressourceneffizienz für Ollama-Modelle
Für Nutzer:innen, die Llama 3.3, DeepSeek R1, Mistral, Gemma 3, Qwen 2.5 oder andere Ollama-Modelle lokal ausführen, bietet Askimo im Jahr 2026 ein umfassendes Ollama Desktop-Erlebnis.
Abschließende Gedanken
Askimo bringt Ollama mit Geschwindigkeit, Struktur und ohne Reibungsverluste auf den Desktop. Lokale Modelle bleiben privat. Deine Unterhaltungen bleiben organisiert. Und deine Prompts werden zu wiederverwendbarem Wissen statt zu Wegwerf-Kommandos.
Sobald du mit Ollama eingerichtet bist, unterstützt Askimo auch automatisierte Workflows, KI-Agenten und MCP-Toolintegrationen für fortgeschrittene Anwendungsfälle. Entdecke die Möglichkeiten auf der Feature-Seite.
Probiere Askimo jetzt aus: 👉 https://askimo.chat/download/
Du hast Feedback oder Feature-Wünsche? Starre das Repo und eröffne ein Issue.